基于MovieLens的用户画像建模报告
报告背景
用户画像是一种将用户属性、行为和好恶等信息转化为标签并关联而形成的用户模型。其目的是连接用户需求和产品运营,帮助企业更高效、更精准的认识、理解用户,从而更有效的分配资源提供为用户提供产品和服务、提高运营效率。
Ta是一个怎样的人?
男性,中青年,产品经理,北方人,喜欢美食、宠物和3C和网络游戏(阴阳师和原神)。
本次报告数据来源于MovieLens,通过介绍用户画像建模并将其应用于用户分群和电影推荐的流程,希望读者能够对用户画像有所了解。
用户画像建模
数据集解释
本次报告使用的数据集为MovieLens10K。该数据集为GroupLens从MovieLens网站收集并提供的用户、电影和评分数据。发布时间为2009年1月1日。
数据集文件结构
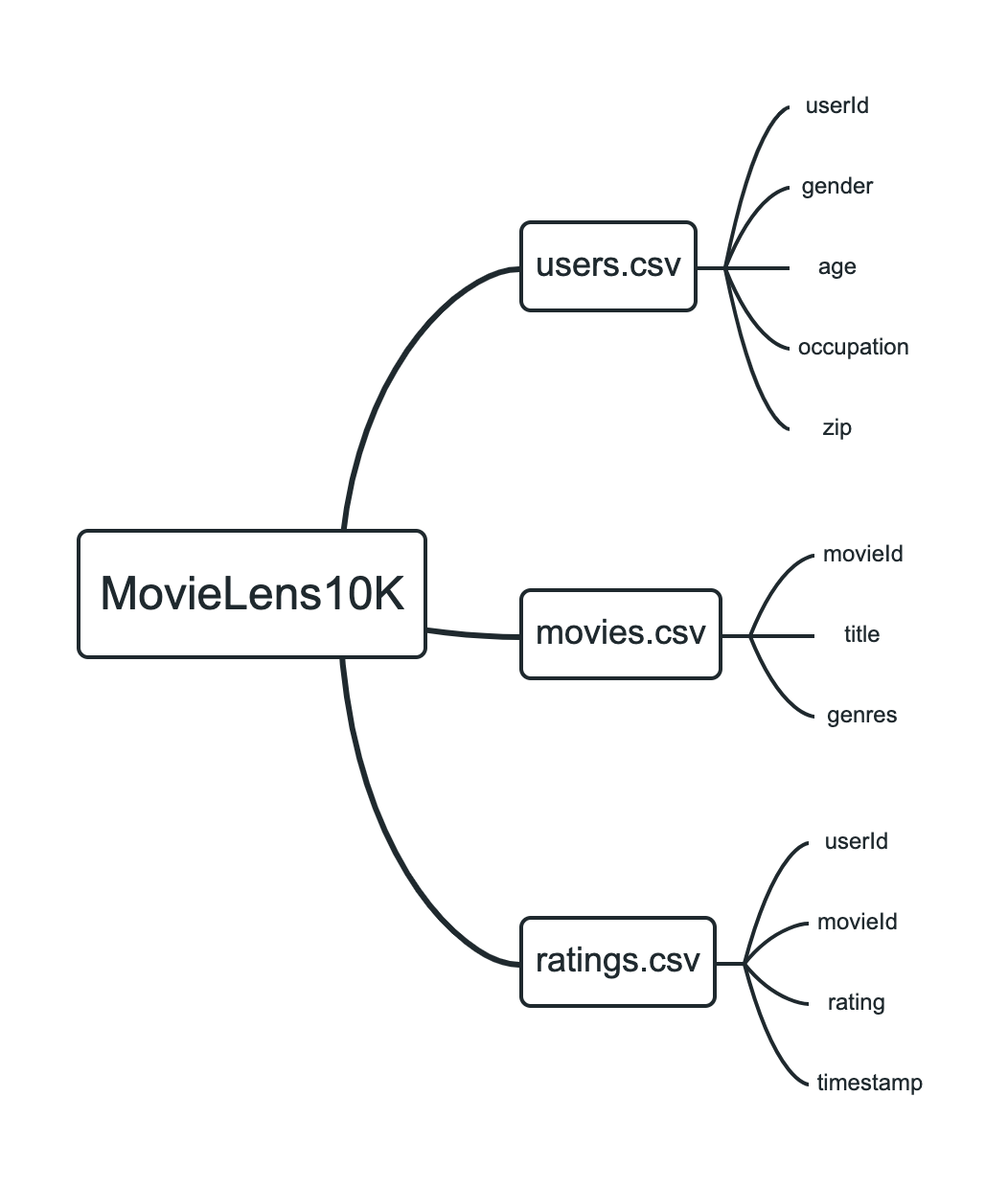
建模流程
获取数据
通过打开本地数据文件获取数据集,其中用户数为{{users}},电影数为{{movies}},评分数为{{ratings}}。
构建标签体系
考虑本次报告所构建的用户画像将应用于用户分群和电影推荐,设计标签分类如下:
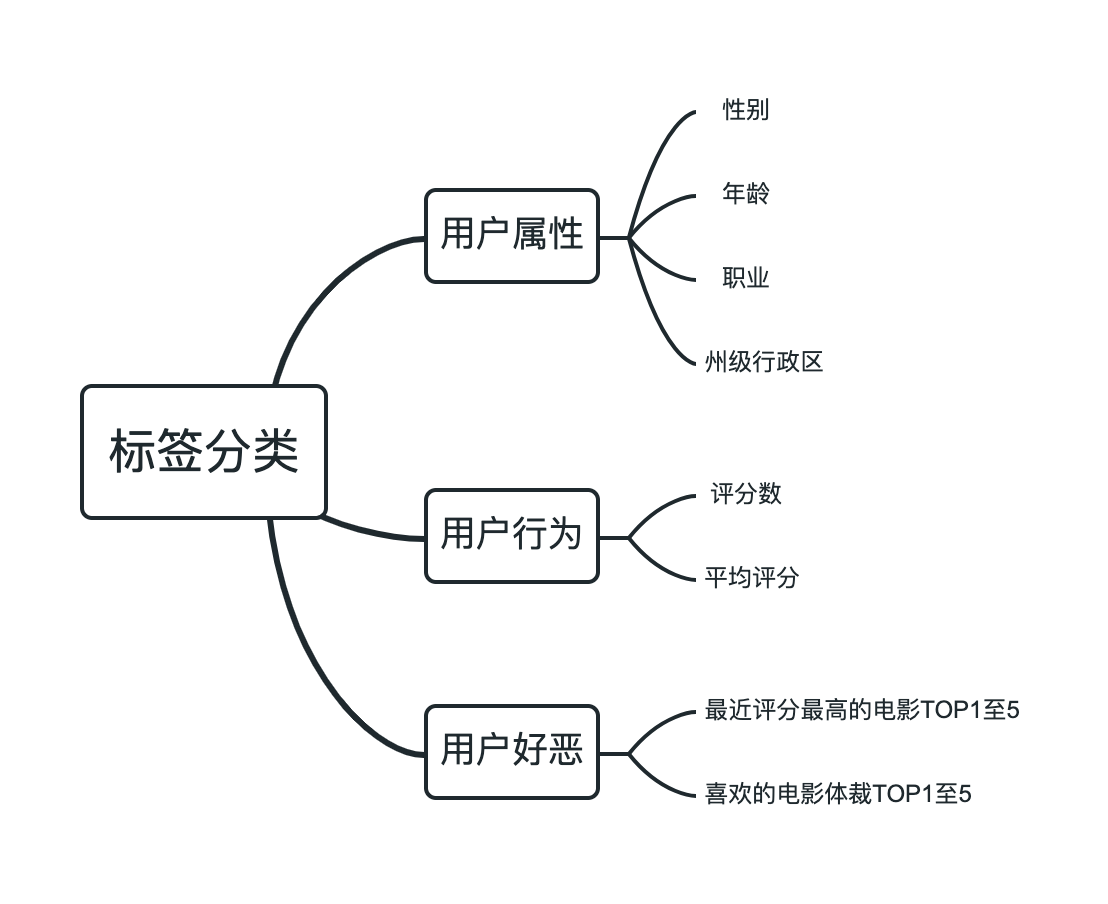
因为在用户分群时将使用基于核函数的主成分分析算法和K均值聚类算法、电影推荐时将使用Apriori算法,所以本次报告使用独热编码方法生成标签。
独热编码(One-Hot Encoding)
一种将称名或顺序型特征转化为机器学习算法容易处理的格式的方法,它为特征的每个值衍生一个二进制的新特征。在该衍生特征中,如果某份样本属于该特征值则为1,否则为0。
例如,“性别”特征将会衍生“gender: male”和“gender: female”两个新特征,并会为所有样本按照衍生特征赋值0/1。其中,男性为{“gender:male”: 1},{“gender:female”: 0};女性为{“gender:male”: 0},{“gender:female”: 1}。
整体用户画像
通过各特征来描绘用户整体画像。
性别
年龄
定义年龄小于18岁为“age: under18”,18至24岁为“age: 18~24”,25至34岁为“age: 25~34”,35至44岁为“age: 35~44”,45至54岁至“age: 45~54”,大于54岁为“age: above54”。
职业
州级行政区
根据邮政编码(美国)解析州级行政区。
评分数
统计每位用户评分数并按照等频分箱、分箱数为5。
平均评分
统计每位用户平均评分并定义为平均评分并按照等频分箱、分箱数为5。
最近评分最高的电影TOP1至5
统计每位用户最近评分最高的电影前五名并定义为最喜欢的电影TOP1至5。
喜欢的电影体裁TOP1至5
统计每位用户评分过的电影体裁数前五名并定义为喜欢的电影体裁TOP1至5。
用户分群
按照用户标签的关联性进行归类分组,企业可以将用户群体划分为具有相似属性、行为和好恶的细分群体。
算法说明
本次报告首先使用基于核函数的主成分分析算法就衍生特征进行降维处理,最后使用K均值聚类算法进行聚类处理并基于间隔统计量确定最优聚类簇数,最终实现用户分群目的。
基于核函数的主成分分析
首先使用核函数(例如径向基)方法,将高维且线性不可分的数据映射到更高维但线性可分的特征空间,最后在该特征空间使用主成分分析算法进行降维处理。
主成分分析
一种常用的数据降维和特征提取的统计方法,其假设是数据内在存在线性关系,通过将数据转换到由主成分构成的坐标系统,从而在最大保留数据信息的前提下降维。
核函数
考虑本次报告使用独热编码方法生成的标签数据具有高维性和稀疏性,通常使用基于余弦相似度核函数(Cosine Similarity Kernel)的主成分分析算法的降维效果更好。
K均值聚类
一种无监督学习的基于距离的聚类算法,其目标是将数据点划分为K个簇,使得相同簇的数据点尽可能相同、不同簇的数据点尽可能不同。缺点是需要预先指定聚类簇数,本报告使用间隔统计量确定最优聚类簇数。
间隔统计量(GapStatistic)
用于评估聚类效果的统计方法,公式如下: \[Gap(K)=E(log{D}_{K})-log{D}_{K}\] 其中,\({D}_{K}=\sum {\sum {dist{(x,c)}^{2}}}\)。选择\(Gap(K)>=Gap(K+1)\)的最小K值作为最优聚类簇数。